
What is indexing?
Indexes are used to quickly locate data without having to search every row in a database table. indexes are usually created using one or more columns in the database table. Creating an index on a field in a table creates another data structure that holds the field value and pointer to that record it relates to.
In simple words, if you have to search a particular person phone number in thousands of pages of the phonebook it’ll be difficult for you to search but what if you have character labels like the following image? I’m sure within a few seconds you can able to find it. Database indexing also works in the same way.

Postgres has a few index types but B-trees are by far the most common. They’re good for sorting and matching; and once you understand what they look like under the hood, it’s immediately apparent why.
Let’s take a look at examples 🧐
For explaining indexing I have created one sample database with having a table named employees with attributes id & name with 1M records.
This is how our employees table looks like,

If you see in the Indexes section there is already one index employee_pkey (on creating a table index is created for the primary key column by default). B-Tree indexes are the default option when creating an index without specifying the type
What is B-Tree?
B-Tree stands for Balanced Tree.
It’s NOT a binary tree, which allows a max of 2 child nodes per parent and was designed for in-memory search.
From Wikipedia 👇
In computer science, a B-tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree generalizes the binary search tree, allowing for nodes with more than two children.[2] Unlike other self-balancing binary search trees, the B-tree is well suited for storage systems that read and write relatively large blocks of data, such as disks. It is commonly used in databases and file systems.
Let’s play with some queries to understand
See below 👇 query,
For Demonstration, I have created 1 million records in the employees table,
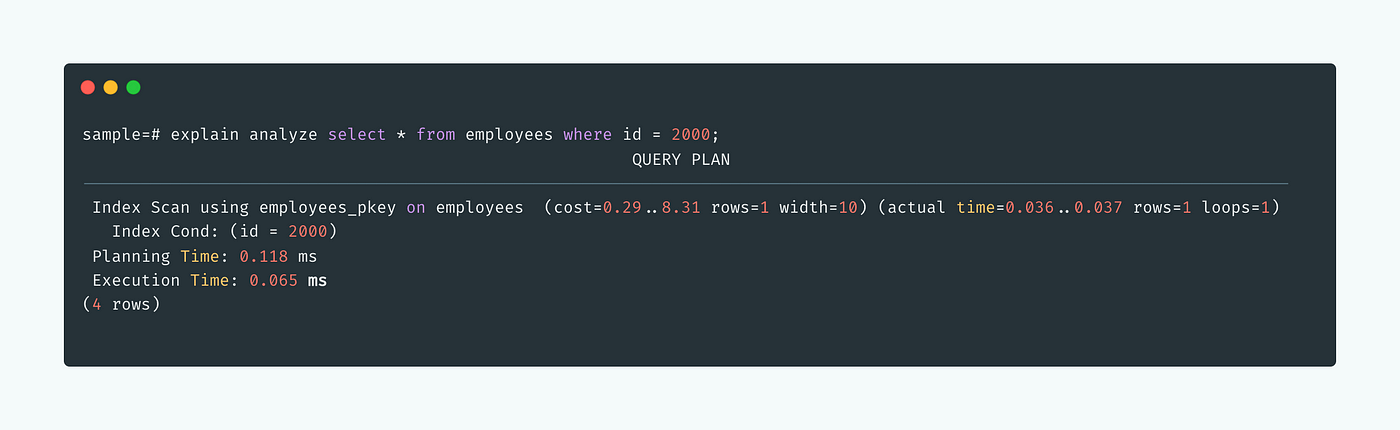
explain analyze select * from employess where id = 2000;
explain analyze gives details like the Execution time, query planning time, Index scan etc.
Look carefully what’s the output of the above query, you can see in the output for this query the execution time is less than a second.
But how this happens, we have around 1 million records in DB and it takes a few ms to fetch a particular record.
Let’s understand how B-Tree indexing works
Indexes in PostgreSQL, simply put, are a replica of the data on the column(s) that is/are indexed. For example, when you search for a record in a table, where the column in which you are searching is indexed, the index decreases the cost of the query because PostgreSQL looks up in the index and can easily find the location of the data on the disk.
B-Trees are “balanced” because the distance from the root to any leaf node is the same. A leaf node is a node without children. The root node is a node at the top.
The node has keys. In our root node below, [1000, 3000, 4000] are keys. keys map to values in a database but also bound keys in the child node.
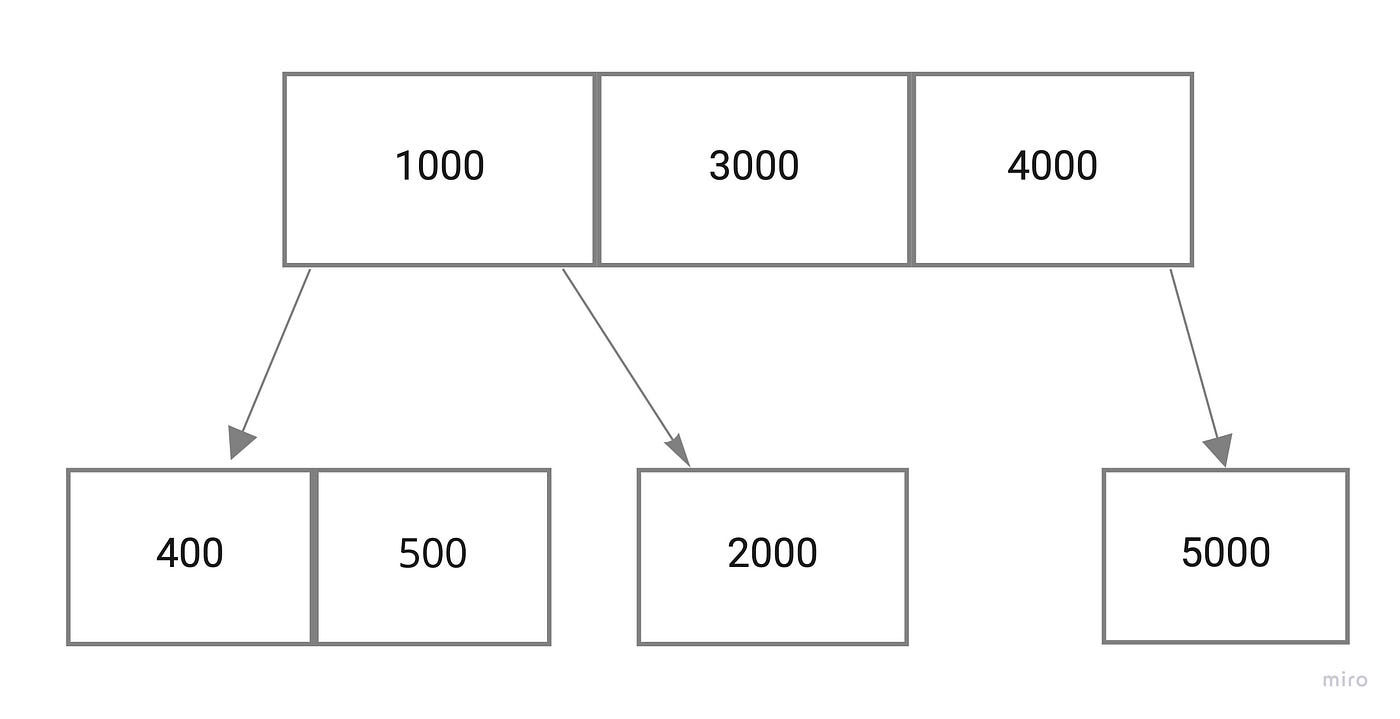
The first child node [400, 500] has values less than 1000, hence the pointer on the left side of 1000.
The second child node [2000] has values greater than 1000, hence the pointer on the right side of 1000.
The third child node [5000] has values greater than 4000, hence the pointer on the right side of 4000.
Now if we wanted to look up the key 2000, we’d compare 2000 to values in the root node and see that it’s between 1000 and 3000. So we’d use the pointer between 1000 and 3000 to find the node containing 2000.
This is an abstraction over Postgres’ implementation but you can already imagine why this is faster than iterating over every number in a table and checking if it equals 2000.
This is why B-trees can search, insert and delete in O(logN) time. for more details about B-tree you can check this link.
Query without indexing,
Now see below query,
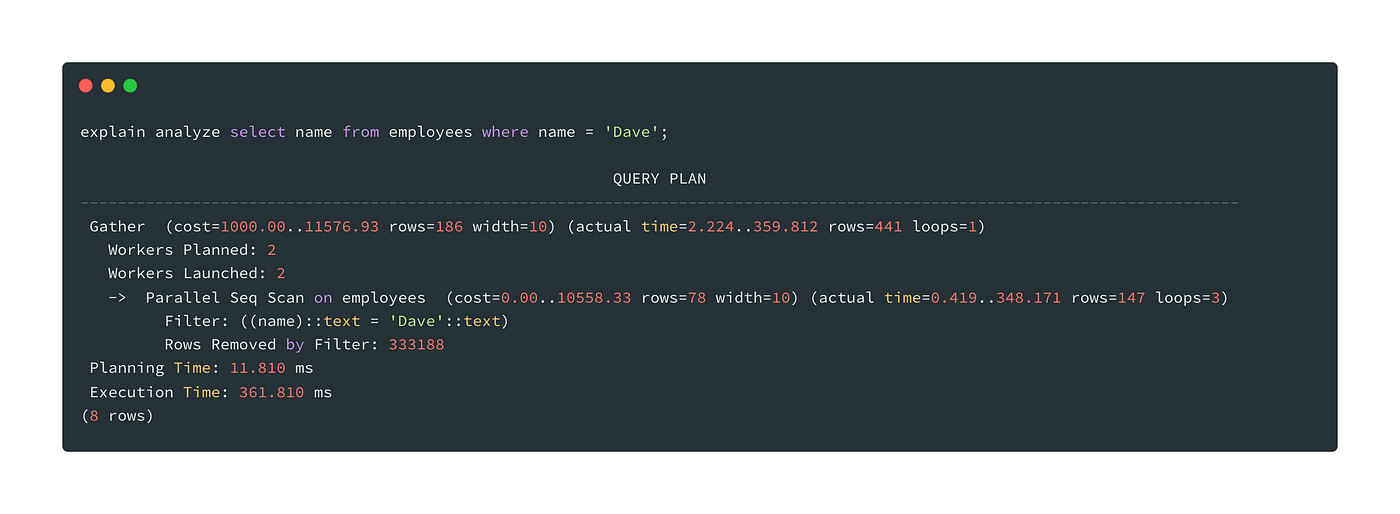
In this query, we’re retrieving employees having name Dave,
See the output of this query,
Query taking more execution time than the first one and this will get worst if we add more data into the table.
You can see in the result Parallel Seq Scan which means the query did a sequential search on the employees table, and that’s why the query takes time to fetch records.
The difference in query time in ordering the indexed vs non-indexed column.

Advantages of Indexing
- It helps you to reduce the total number of I/O operations needed to retrieve that data, so you don’t need to access a row in the database from an index structure.
- Offers Faster search and retrieval of data to users.
- Indexing also helps you to reduce tablespace as you don’t need to link to a row in a table, as there is no need to store the ROWID in the Index. Thus you will be able to reduce the tablespace.
- You can’t sort data in the lead nodes as the value of the primary key classifies it.
Disadvantages of indexing
- SQL Indexing Decrease performance in INSERT, DELETE, and UPDATE query.
- You are not allowed to partition an index-organized table.
At Scalereal We believe in Sharing and Open Source.
So, If you found this helpful please give some claps 👏 and share it with everyone.
Sharing is Caring!
Thank you ;)