
When someone says, “Use Celery to offload the time-consuming tasks”, have you ever thought that what exactly Celery does here to offload the tasks or how Celery works internally 🧐?
I too wondered while working on one of our projects in Django at Scalereal, when we had to run some background tasks (Scheduling and Publishing blogs periodically using Medium, Hashnode, etc APIs) and we executed them using celery.

Out of that curiosity I read about what is Asynchronous Processing and how Celery works and got some basic level of understanding.
In this article, we will see Why do we need Celery? and What is Celery?
Why do we need Celery 🤔?
1. Offloading Tasks
In order to serve the incoming requests our application server needs to be available. Consider, if our application server is also processing the time-consuming tasks Synchronously(wait until ready), it becomes unavailable to serve more incoming requests. To overcome this we can offload these tasks by moving them outside the main request-response cycle. Offloading the time-consuming tasks and executing them asynchronously, shorter the response time which eventually makes the user experience better.
The task which is not required to be completed before serving the response of the request is eligible or a candidate to be offloaded.
⭐ Some examples of commonly offloaded tasks are,
- Sending emails
- Processing images and videos
- Data Analysis
- Report Generation
- Making Third-party requests
2. Running tasks at Schedule
Consider we have to run some code/task every day or every hour which is not included in the request-response cycle. Here Celery can make our life easy by making these tasks work at regular intervals. These tasks are executed by celery workers asynchronously(in the background) at the scheduled time.
⭐ Some examples of scheduling tasks at particular intervals are,
- Send out trail period ending emails.
- Regularly scrape a website and store results in the database.
- Process a batch of data every night.
- Report generation (creating PDF files).
Asynchronous what? have you noticed in both cases asynchronous was common? Let’s deep dive into the concept of Asynchronous Processing.
Asynchronous Processing 🔀
- Asynchronous processing is the opposite of Synchronous processing, as the client does not have to wait for a response after a request is made, and can continue other forms of processing.

- In synchronous processing, our client-server seamlessly executes the APIs in a synchronous HTTP request-response cycle. This request-response cycle is suitable for faster tasks that can be finished within milliseconds.
- However, some time-consuming tasks take more than one or two seconds to execute and are ultimately too slow for synchronous execution.
- Also as I mentioned above(Running tasks at Schedule) there are other tasks that need to be executed in the future which can’t be included in synchronous processing.
- So, the best course of action is to move these tasks outside the execution request-response cycle.
- Simply we need to make sure that our web server notifies another program that certain tasks need to be processed at a later time.
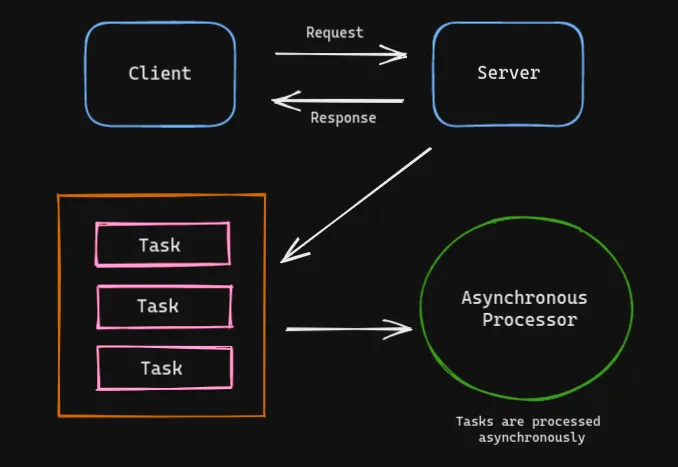
- Now, instead of the time-consuming tasks running as a part of the actual web response, the processing runs separately so that the web application can respond quickly to the request.
- To achieve asynchronous processing, a middleman needs to be inserted between the client and the processing server to allow multiple separate processes to pass information to one another.
- The middle man can be called a message queue, which ingests the request messages and distributes them to the server based on the load the processing server can handle at any given moment.
Message Queue 📂
- Message Queues manage the tasks that must be executed outside the usual HTTP request-response cycle.
- The message is the data to be sent from producer to consumer. Message queues don’t process message and simply stores them.
- We can consider the producer as a client application that produces messages on the basis of user interactions and the consumers are the services that can process the arriving messages.
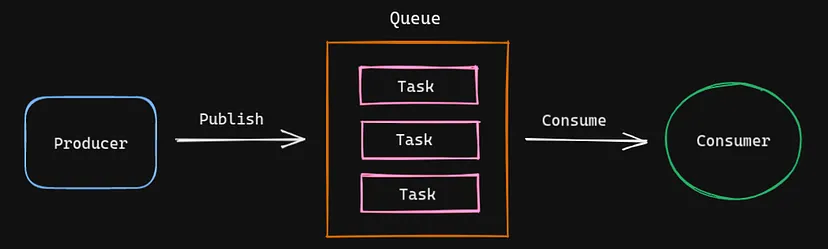
- So with the message queues, producers don’t have to wait for the consumers to become available and can add messages to the queue.
Also, consumers can process messages whenever they are available. Eventually, there will be no overhead in waiting.
Till now we got enough knowledge about Asynchronous Processing and all the related stuff. Now let’s deep dive into the concept of Celery.
What is Celery?

As per the definition, Celery is a powerful, production-ready asynchronous job queue, which allows you to run time-consuming Python functions in the background. A Celery powered application can respond to user requests quickly, while long-running tasks are passed onto the queue.
Let’s see its internal working and workflow.
Internal Working
The internal working of Celery can be stated as the Producer/Consumer model as we discussed above.
Producer
Producers are basically web services that handle web requests. During the request processing, the time-taking tasks or the periodic tasks are pushed into the message queue.
- Queue
Celery communicates via messages, usually using a broker to mediate between clients and workers. To initiate a task the client adds a message to the queue(the broker) and then delivers that message to a worker. Here the queue can be referred to as Redis, RabbitMQ, or many other services supported by Celery.
- Consumers
Consumers are the worker nodes. The main difference between the web and worker is that web nodes receive requests from the internet and place tasks to be processed asynchronously in the queue and worker nodes are the machines that pick these tasks and execute them.
Celery-Django Workflow 💡

Here we can see the workflow of Celery and Django when the user sign’s up on the particular website and receives an onboarding email.
- After receiving the client’s request the Django server enqueues a new task(python function to send email) in the Redis(an in-memory data store) which works as a message queue.
- These tasks will not run on our main Django webserver. Instead, Celery will manage separate servers that can run the tasks simultaneously in the background.
- The Celery worker picks up the task from the queue and executes it asynchronously which enables the web application to respond quickly to the request.
- Whenever a new task arrives, one worker picks it up and processes it.
- Hence celery decreased the performance load from web application by running the functionality of the Django server asynchronously.
So far we have learned the need for Celery, Asynchronous processing, Message Queues, and what is Celery. In the next part, we will learn how to integrate Celery and Redis with Django and run tasks asynchronously.
At Scalereal We believe in Sharing and Open Source.
So, If you found this helpful please give some claps 👏 and share it with everyone.
Sharing is Caring!
Thank you ;)